






前回はざっくりとしたアルゴリズムの概要について触れさせていただきました。
一概にアルゴリズムといってもいくつか種類がありますし「どれから勉強すればいいの」ってなりますよね。
情報技術者試験などでは『探索アルゴリズム』『ソートアルゴリズム』の2つが主に出題されているようです。
では、今回はそのうちの探索アルゴリズムについて触れていきたいと思います。
本ページでは探索アルゴリズムのみに触れていきます。
ソートアルゴリズムについては、探索アルゴリズムを理解したうえで学習した方が頭に入っていきやすいのかなというのが個人的見解でした。なぜかというと探索アルゴリズムを理解していないと
「何のためにソートアルゴリズムが存在しているのかわからない」
という状況になりかねないので…。
これから学習する方は、ぜひ探索アルゴリズムから理解していただけたらと思います。
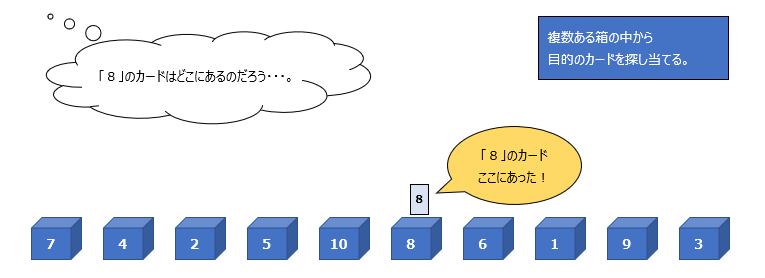
端的に申し上げると
複数あるデータ群の中から目的のデータを探し出すアルゴリズムを探索アルゴリズム(もしくはサーチアルゴリズム)と呼びます。
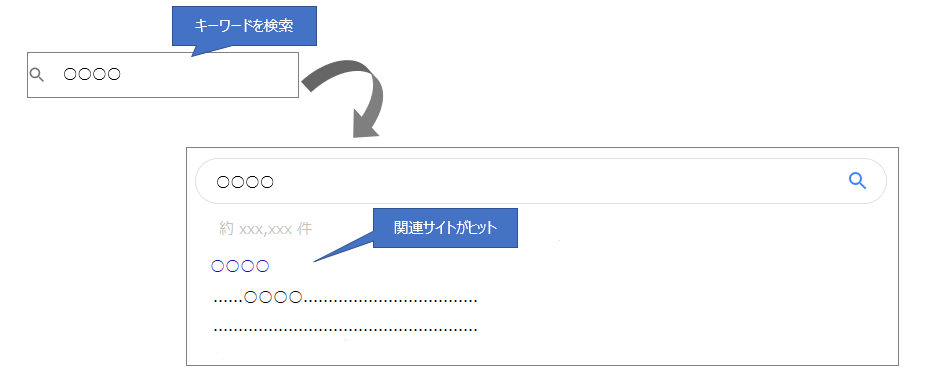
例えば皆さんインターネットで何か調べものをする際、GoogleやYahoo!などの検索サイトを使用しますよね。
検索サイトでキーワードを入力し実行すれば、キーワードに関連されたサイトが検索結果として出力されます。
このように膨大なデータの海から特定の情報を探索することにも探索アルゴリズムが関わっています。
複数あるデータ群から目的のデータを探し出す方法は複数あります。
その中で代表的な検索方法である『線形探索』『二分探索』『ハッシュ探索』をご紹介致します。
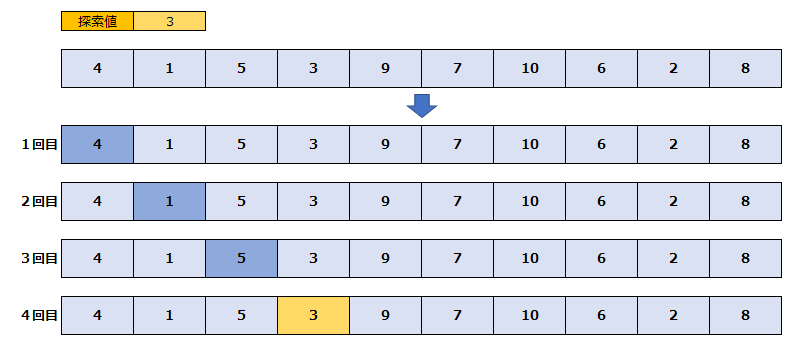
線形探索は、データ群の端から1つずつ順番に探索対象であるかチェックしていく探索方法です。最もシンプルな探索方法ですが、逆に言うと、線形探索を理解していないと他の探索方法を理解できないため、覚えておきたい基本の知識となります。
例えば下記のようなフローチャートに置き換えてみます。
※フローチャートの変数は下記を使用します。

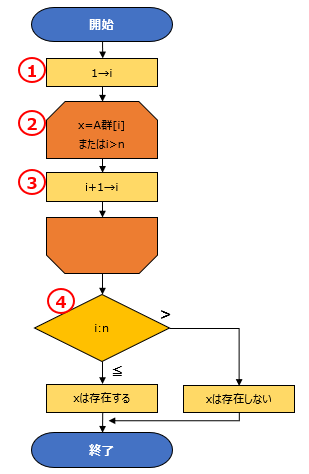
<動作概要>
① 添字iを1で初期化する。
② xとA群(i)の値が等しい、またはiの値がnより大きい場合ループを終了する。
③ i+1の値をiにする。
④ iがnより小さいか、またはiがnより大きいか判断する。
②でxとA群(i)の値が等しくない、またはiの値がnより大きくない場合は、③で添字iに1を加算し、A群[i]が示す箇所を1つ移動する。
そして再度②でxとA群(i)の値を比較する。これをxとA群(i)の値が等しくなるまでループする。
②でxとA群(i)の値が等しいとなった場合は、④でiがn以下か以上か判断する。
iがn以下の場合「xは存在する」へ進む。配列内に探索値があったということになる。
iがn以上の場合「xは存在しない」へ進む。配列内に探索値がなかったということになる。
先頭から順にチェックし、探索値が見つかったらループ終了という条件で探索していくのが、線形探索というわけです。
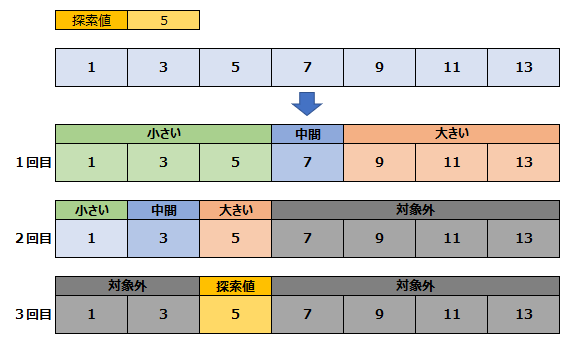
配列の中間にある値をチェックし、探索対象がそれよりも「大きい」「小さい」などで切り分けていく探索方法です。ただし前提として探索対象のデータ群があらかじめ、「昇順」や「降順」といった規則性を持っている場合のみに使用できます。
例えば下記のようなフローチャートに置き換えてみます。
※フローチャートの変数は下記を使用します。
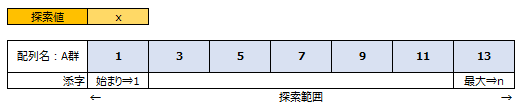
<動作概要>
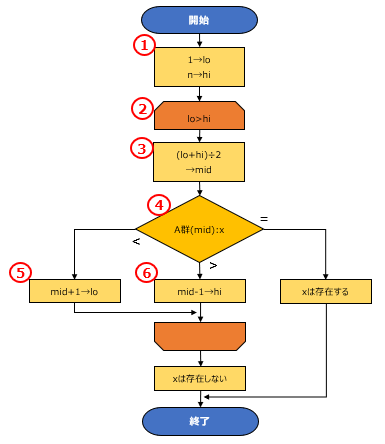
① 探索範囲の下限値loを1で、上限値hiをnで初期化する。
② loの値がhiより大きい場合ループを終了する。
③ lo+hi÷2の値を探索範囲の中間midにする。
④ A群(mid)がxの値より大きいか、小さいか、または等しいか判断する。
⑤ mid+1の値をloにする。
⑥ mid+1の値をhiにする。
②でhiよりloの値が大きくない場合は、③でloとhiを加算し2で除算、算出した値を探索範囲の中間midとする。
②でhiよりloの値が大きい場合は、「xは存在しない」へ進む。探索値がなかったということになる。
④でA群(mid)よりxの値が大きいか、小さいか、等しいかを判断する。
④でA群(mid)よりxの値が大きい場合は⑤に進み、でmidへ1を加算した値をloとし、loが示す箇所を移動する。そして②へループする。
④でA群(mid)よりxの値が小さい場合は⑥に進み、でmidから1を減算した値をhiとし、hiが示す箇所を移動する。そして②へループする。
④でA群(mid)よりxの値が小さい場合はループを抜け、「xは存在する」へ進む。配列内に探索値があったということになる。
値の小さいグループと値の大きいグループを移動させながらループし、探索範囲を絞り込んで探索していくのが、二分探索というわけです。探索対象のデータ群があらかじめ、「昇順」や「降順」といった規則性を持っているという前提さえ満たしていれば、膨大なデータを処理する際は、線形探索より効率の良い探索方法と言えるでしょう。
ハッシュ関数と呼ばれる計算式を用いて、データの格納位置を参照する探索方法です。ただし前提としてデータ格納時に、同じハッシュ関数を用いた計算式で求める位置へと格納されている必要があります。
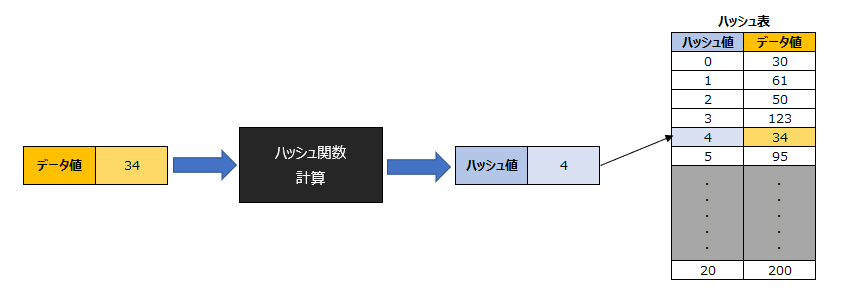
例えば今回は、5桁の数 a₁ a₂ a₃ a₄ a₅ をmod(a₁+a₂+a₃+a₄+a₅,20)というハッシュ関数を用いて位置が決められ格納されているとします。
※modは余りを求める関数です。
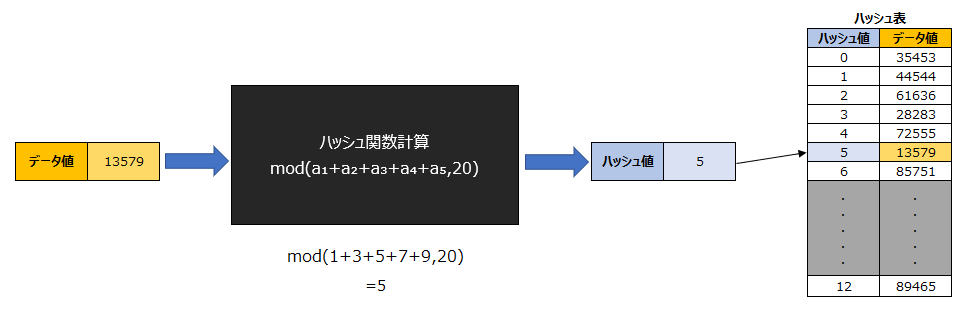
データ値「13579」のハッシュ置を探索するハッシュ関数
mod(1+3+5+7+9,20)
=mod(25,20)
=5
ハッシュ値「5」がデータ値「13579」の格納位置ということになる。
探索対象データをハッシュ関数に織り交ぜ、探索対象の格納位置をピンポイントで参照する方法がハッシュ探索というわけです。他の探索方法と比べて圧倒的に小さい計算量で探索を行える非常に優れた探索方法ですが、前提として格納時にハッシュ関数を用いた計算式で格納されている必要があるということです。また格納位置が同じになってしまう計算式が他にあると、衝突(シノニムという現象)が発生してしまうので、結果が重複していないハッシュ関数で格納されている必要もあります。
アルゴリズムの時間計算量は、O記法(オーキホウ、もしくはオーダキホウと読む)と呼ばれる記法で記述します。O記法はおおまかな処理効率を計るための指標となります。
取り扱う要素数n(nは十分大きい数と仮定)を処理する際、Oと()を使い、()の中に、処理の繰り返し最大の場合の回数をnを使った式で記述します。
nが十分大きいため、O記法の()の中のnを使った式のnの定数倍やnの2番目以降の次元の項は省略とします。
例えば
3nの時は、O記法では3nの定数を省略してO(n)と記述し、3×(nの2乗)
+5nの時は、次元の小さい項5nは省略して、さらに、定数3も省略されO(nの2乗)と記述します。
O(n)
核となる処理をn回繰り返す、nが増えた分処理の回数が増えていくので時間計算量はO(n)となります。
O(log n)
nが十分大きい数であることを前提として考えているので、対数の底が2でも10でも誤差の範囲とし、計算量としてO記法で書く際は、底なし表記します。よって時間計算量はO(log n)となります。
O(1)
直接アクセスでき、件数nに左右されないので時間計算量はO(1)となります。

今回は、探索アルゴリズムに視点を置いてご紹介致しましたが、これらは皆さんが日常で使われているTwitterやFacebook、InstagramなどのSNS(ソーシャル・ネットワーキング・サービス)にも活用されています。知りたい情報に関連する内容がすぐに検索され時間を効率的に使える、もはや探索アルゴリズムは、ビジネス社会に欠かせないものになっているのかもしれませんね。
今回ご紹介できませんでしたが、ソートアルゴリズムについても重要な役割を担っています。探索対象のデータ群があらかじめ、「昇順」や「降順」などの規則性あることを必要としている、二分探索と強い繋がりがあります。
ぜひ興味を持たれましたら、ソートアルゴリズムについても学習をしてみてください。

